
Identity and Access Management
April 11th 2020

Contents
- Who Are You?
- Overview
-
Identity and Authentication
- Authentication Methods
- Username and Passwords
- Single Sign-ON (SSO)
- Multi-Factor Authentication
- Passwordless
- Biometric Authentication
- Token
-
Passwords
- Plain Text Password
- Brute Force Attack
- Data Handling and Logging
- Encryption
- Using Encryption
- Asymmetric Encryption
- Hashing
- Hashing with Salts
-
Access and Authorization
- Decoding JWT using Javascript
-
Alternate Atrack Vectors
- Phishing
- Social Engineering
- Staying Ahead of the Attackers
Overview
유저 인증을 위해 가장 일반적으로 아이디와 비밀번호를 이용한 로그인 방법이 있습니다. 비밀번호는 매우 조심히 디뤄야 하기 때문에, 포스팅을 통해 로그인 방법과 비밀번호를 다루는 방식에 대해 알아보려 해요. 그리고 이러한 정보를 데이터베이스 또는 다른 방식을 이용해 저장하는 법에 대해서 살펴보겠습니다. 일반 텍스트로 비밀번호를 데이터베이스에 저장할 수는 없으니까요.
유저가 요청을 보낼때마다 아이디와 비밀번호를 입력하게 하면 너무 불편하겠죠. 따라서, 토큰에 대해서도 알아볼게요. 토큰은 클라이언트 측에 임시로 저장해 사용할 수 있는 일종의 인증서라고 볼 수 있어요.
우리가 인증 절차를 사용하는 이유는 민감한 정보는 특정 유저만 접근할 수 있도록 하기 위해서에요. 하지만, 이러한 시스템을 직접 구축 했을 때 수반되는 리스크가 있습니다. 이러한 리스크를 줄이며 사용할 수 있는 3rd-party 라이브러리에 대해서도 알아볼거에요. 😀
Who Are You?
Authentication 에 대해 간단히 말하면, 여러분이 설계한 디지털 시스템에 요청을 한 사람이 누구인지 확인하는 작업이에요. 실생활에서 예를 찾아 보면 신분증을 이용해 운전 중 경찰이 신원 확인을 하거나, 술집에서 술을 주문하는 것이 있습니다. 디지털 상에서는 아이디, 비밀번호를 이용하거나 two-factor 인증을 통해 위와 같은 작업을 할 수 있습니다.
Identity and Authentication
Authentication Methods
Username and Passwords (Password is Not Ideal)
유저 인증을 위해 아이디와 비밀번호를 사용하는 경우입니다. 클라이언트에서 유저가 입력한 아이디, 비밀번호를 API 서버에 전달하면, API 서버는 데이터베이스의 유저 정보와 비교 후 200, 401(Unauthorized), 403(Forbidden) 등의 Status Code와 함께 클라이언트에 응답을 보냅니다.
비밀번호 인증을 많이 사용하지만, 이 비밀번호가 인증 절차에 이상적이지는 않습니다. 여러 문제가 있지만 크게 유저 측면과 개발자 측면 두 가지 관점에서 살펴볼 수 있습니다.
유저 측면에서의 문제점
- 비밀번호를 잊어버림.
- 쉬운 비밀번호를 사용함.
- 다른 서비스와 같은 비밀번호를 사용함.
- 비밀번호를 공유함.
개발자 측면에서의 문제점
- 기술적인 책임감이 따름. 구현이 쉬운 방법을 택해 개발을 할 수 있으며, 이 경우 비밀번호 노출 우려가 생김.
- 비밀번호 확인 시 로직이나 개발적인 면에서 개발자 실수가 생길 수 있음.
Single Sign-ON (SSO)
Single Sign-On은 누가 자신의 서비스에 요청을 하는지에 대해, 제 3자의 서비스를 이용하는 것이에요. SSO 의 가장 큰 장점은 큰 시스템을 갖춘 업체의 유저 인증을 이용하는 것이기 때문에, 직접 유저 인증 절차를 구현할 필요가 없다는 것이랍니다.
Multi-Factor Authentication
비밀번호 이용 시 유저가 비밀번호를 공유하게 되면 다른 사람이 이것을 오용할 수 있어요. Multi-Factor는 인증 절차를 한 단계 추가해 보안을 강화하는 방법이에요.

유저가 아이디, 패스워드로 인증 절차를 완료하면 추가 코드를 해당 유저가 소유한 특정 디바이스나 다른 서비스 계정으로 발송을 합니다. 전달 받은 코드를 유저가 입력하면 인증 절차가 완료됩니다. Multi-Factor 인증에는 종종 Decaying Temporal Algorithm이 사용된다고 해요. 일정 시간 동안만 유효한 암호화된 코드를 생성해 특정 디바이스와 서비스만 해당 코드를 알 수 있도록 하는 방식이에요.
Passwordless
아이디, 패스워드 인증 절차 시 보안 강화를 위한 방법으로 Multi-Factor 인증을 간단히 봤어요. Multi-Factor 흐름에서 취약한 부분이 비밀번호인데, 이 비밀번호 절차를 없애고 유저 인증을 진행하는 방법이 있습니다. 유저는 비밀번호를 제외한 인증을 원하는 아이디만 입력하면 됩니다. 대표적인 예로 슬랙이 있습니다.
Biometric Authentication
핸드폰 이용시 지문 인식을 많이 사용하는데, 인증을 위해 이와 같이 생체 인식 방법을 사용할 수 있어요. 다른 방법에 비해 보안성이 높은 편입니다.
Third-Party Auth System
인증 절차 구축 시 대부분의 리스크는 백엔드 영역에서 발생해요.

규모가 그리 크지 않으면, API 서버에서 인증까지 관리하는 것이 수월할 거에요. 하지만, 서로 의존성이 생길 수 있어 시간이 흐르면 유지보수가 어려워 질 수 있어요.
때문에, Microservice 구조로 개발을 하기도 합니다. 특정 목적을 가지는 개별 서버를 구축하는 것인데, 이때 개별 서버마다 인증 시스템을 가지고 있으면 수정 사항이 생길때마다 여러곳을 일일이 수정해야 해요. 이러한 경우 인증 시스템을 별도의 마이크로서비스로 구축할 수도 있어요.

Authentication System을 직접 구축할 수도 있지만, 필요에 따라 이미 잘 구축된 서비스를 이용할 수도 있습니다. 예로, Auth0 또는 AWS의 Cognito, Firebase와 같은 서비스를 들 수 있어요.
위와 같이 유저 인증에 관련된 몇가지 방법에 대해 알아 보았어요. 개발자로서 이러한 여러 방법에 대해 인지하고, 개발하는 애플리케이션에서 데이터를 다룰 때 얼마나 높은 보안성이 필요한지에 따라 기준을 세워 적절히 믹싱해서 사용할 수 있도록 해야겠습니다.
Token
유저 로그인이 정상적으로 완료되면, 토큰을 받습니다. 필요한 API Service에 요청을 보낼 때 이 토큰을 이용합니다. 전통적으로 서버에서 유효한 토큰인지 확인을 위해 Session Table을 이용했습니다. 데이터베이스에 User ID와 Session Id 페어를 가지고, 요청을 받은 API 서버는 데이터베이스를 통해 이것이 유효한지 확인을 합니다.
하지만, 마이크로서비스에서 개별 서비스에 걸쳐 이러한 상태를 유지하는 것이 쉽지는 않을 거에요. Session을 체크하기 위해 요청 중 latency가 생길 수도 있고, 또한 여러 다른 Stack을 거치며 Session 이 변경될 수도 있어요. 이러한 변경이 시스템 전체에 반영되려면 어느 정도 시간이 또 소요될 것입니다.
때문에, 우리는 서버에서 토큰이 유효한지 아닌지 판단할 수 있는 stateless한 방법이 필요할거에요. jwt 토큰은 본질적으로 Stateless 합니다. 클라이언트로부터 서버가 jwt 토큰을 받으면 서버는 인증 서버로부터 public key 를 받아 저장합니다. 이 public key를 이용해 API 서버는 토큰의 유효성을 확인합니다. 그러면 API 서버는 이 토큰을 기반으로 누가 요청을 보낸 것인지, 토큰은 유효한 것인지 알 수 있어야 합니다.
Datastructure
jwt는 header.payload.signature의 형식을 가지는 string 입니다. jwt는 특정 데이터를 가지고 있는 string이며, 간단한 알고리즘인 base64를 이용해 인코딩 되었습니다.
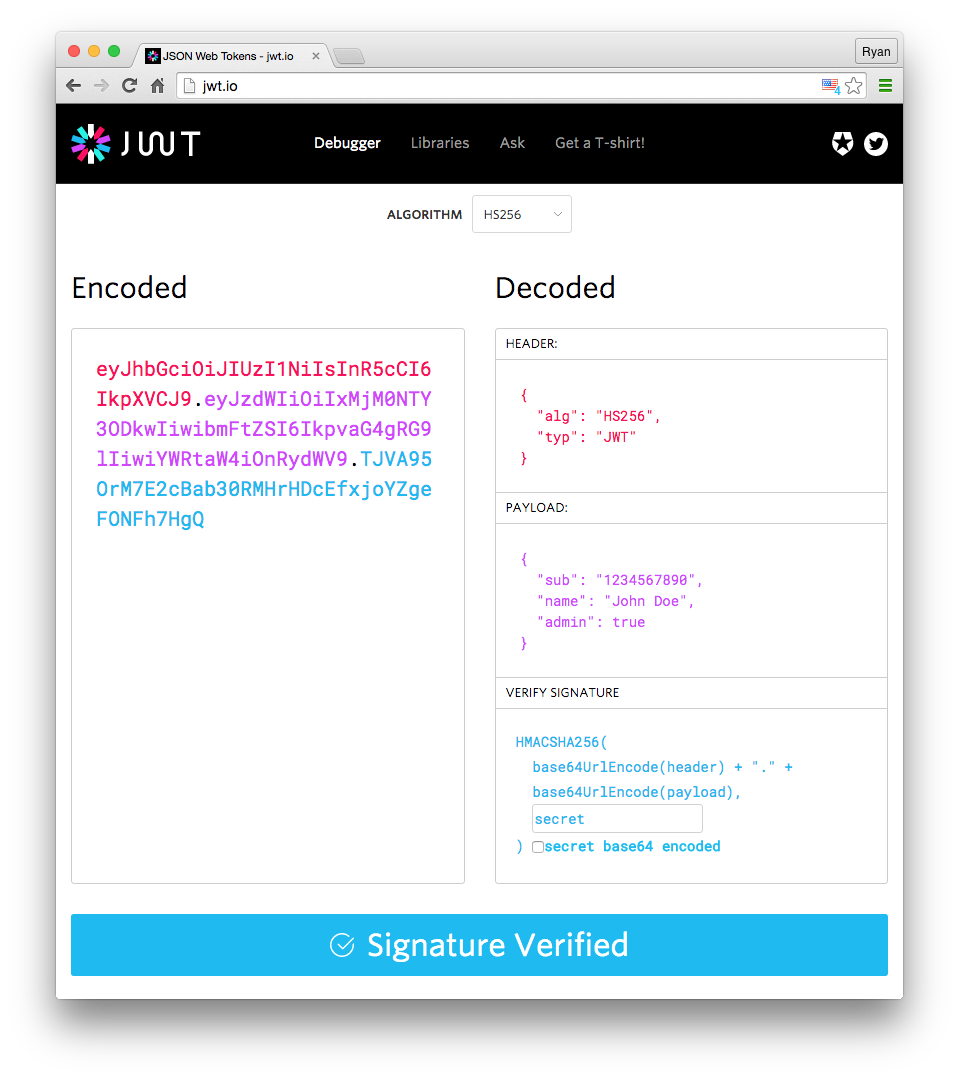
payload를 base64를 통해 디코딩 후, 위와 같이 username과 같은 정보를 얻었어요. payload에 username또는 아이디 등을 포함해 API 서버가 유저를 확인할 수 있습니다. 유의할 점은 이 payload 는 쉽게 디코딩 할 수 있는 정보이기 때문에, 비밀번호와 같은 민감한 정보는 여기에 포함하면 안 돼요. JWT토큰은 base64 방식을 이용하면 누구나 손쉽게 만들수 있어요. 때문에, 다음으로 이 토큰이 우리가 신뢰할 수 있는 시스템에서 생성된 토큰인지도 확인을 해야 해요.
Validation
jwt 내 정보가 유효한 것인지 알기 위해 signature 파트가 사용됩니다. 확인 작업을 위해 header, payload, secret을 인자로 받아 signature를 반환하는 함수가 필요합니다. secret은 Authentication server 와 API server에 저장 돼 있는 string 이에요.

API 서버에서 요청 시 받은 jwt에서 확인한 signature가 다를 경우, 해당 토큰은 유효하지 않다고 판단할 수 있어요.
Storing Token
클라이언트가 API 서버에 매 요청을 보낼 때마다 인증 과정을 거치려면 매우 번거롭겠죠. 따라서, 클라이언트에서 필요한 작업을 해야 해요. 이를 위해 jwt 를 클라이언트 측에 저장하고 되찾을 수 있는 기능이 필요합니다.

여기서 클라이언트는 웹브라우저로 간주할게요. 브라우저에서 persistent memory에 데이터를 저장하기 위해 localStorage를 이용할 수 있어요. localStorage를 이용하면 브라우저에서 domain에 존속된 key-value pair 데이터 를 저장할 수 있어요. localStorage는 토큰을 저장하는 일반적인 방법 중 하나이지만, localStorage 사용 시 리스크도 존재하기 때문에 개발자로서 이를 인지하고 사용할 필요가 있어요.

Cross-Site Scripting Attacks(XSS)를 이용해 다른 나쁜 의도를 가진 서버에서 localStorage에 접근할 수도 있기 때문이에요. localStorage에 저장된 토큰은 유효한 것이기 때문에, 나쁜 의도로 접근한 서버에서 스크립트를 주입해 이를 악용할 가능성이 있어요. 심한 경우 DOM 에 버튼, 폼 등을 삽입해 유저 정보를 자신의 서버로 빼돌리 수도 있을 거에요. 이 리스크를 줄이기 아래와 같이 sanitize 작업을 해 주어야 합니다.

또다른 리스크 중 하나는 3rd-party 라이브러리 사용 시 주입 가능성이 있는 스크립트입니다. 프론트엔드 개발을 진행할 때 많은 npm module을 사용합니다. 이러한 경우 신뢰가 있는 dependency 를 사용하는 것이 중요해요. 데이터 스크래핑을 위해 코드 몇 줄 삽입하는 것은 그들 입장에서는 쉬운 작업이기 때문입니다.
그래서 jwt 토큰 이용 시 아래와 같이 최소 유의 사항을 인지하면 좋을거 같아요.
- 민감한 정보는 payload에 포함하지 않기
- 토큰은 일정 기간 단위로 만료 시키기
토큰을 저장하기 위해 localStorage를 이용한 이유는 도메인에 종속된 데이터를 간직하기 위해서에요. 같은 기능을 위해서 쿠키를 이용할 수도 있어요. 쿠키에는 또한 http only 속성이 있어, 이를 이용하면 자바스크립트 코드로 쿠키에 접근할 할 수 없어요.
Sending Token
클라이언트 측에 저장한 토큰을 API 서버에 요청 시 헤더에 포함해 전달을 하고, 서버에서 토큰 유무 및 유효성에 따라 클라이언트에 응답을 보내게 됩니다. 서버에서 헤더의 토큰을 확인하는 함수를 아래의 예와 같이 작성해 볼 수 있어요.
def get_token_auth_header():
if "Authorization" not in request.headers:
abort(401)
auth_header = request.headers["AUTHORIZATION"]
header_parts = auth_header.split(" ")
if len(header_parts) != 2:
abort(401)
elif header_parts[0].lower() != "bearer":
abort(401)
return header_parts[1]
위에 작성한 함수를 이용해 헤더 확인 후 클라이언트에 응답을 보냅니다. 데코레이터를 이용해 리팩토링 후 API 엔드포인트에 적용해 볼 수 있습니다.
from flask import Flask, request
from functools import wraps
app = Flask(__name__)
def require_auth(f):
@wraps(f)
def wrapper(*args, **kwargs):
token = get_token_auth_header()
try:
payload = verify_decode_jwt(token)
except:
abort(401)
return f(jwt, *args, **kwargs)
return wrapper
@app.route("/headers")
@require_auth
def headers(payload):
print(payload)
return "Access Granted"
여기까지 기본적인 여러 인증 방법과, jwt가 유효한지 확인 및 승인 절차를 코드에 적용하는 방법에 대해 간단히 살펴보았어요.
Password
비밀번호는 유저가 안전하게 다루지 않을 수 있고, 개발자 또한 비밀번호 인증을 쉬운 방법으로 구현하면 위험에 노출될 수 있어요. 그리고, 개발자의 실수로 데이터베이스에 있는 유저 정보가 노출될 가능성도 있습니다. 또는 API 서버에서 취약점이 있으면 이를 이용해 데이터베이스에 접근할 가능성이 있어 보안에 대한 개발자의 책임 또한 중효합니다.
이러한 위험은 코드 단계에서 뿐만 아니라 시스템이 커뮤니케이션 하는 방식에서도 존재할 수 있어요. 프론트엔드에서 API 서버로, API 서버에서 데이터베이스로 데이터가 옮겨가는 과정에서도 위험이 있을 수 있습니다. 때문에, 나쁜 의도로 유저 정보에 접근하려는 방법에 대해서도 알아보고, 이를 경감 시킬 수 있는 방법에 대해서도 인지가 필요합니다.
Plain Text Password
비밀번호를 일반 텍스트로 저장 후 유저 로그인 시 비교하는 방법은 매우 쉽습니다. 이러 방식의 구현은 없을 거라 생각하기 쉽지만, 이로 인한 문제가 생각보다 빈번히 발생하고 있다고 하네요. 이 문제가 발생하는 이유는 구현이 쉽다는 점 때문이에요.
- Facebook stored hundreds of millions of passwords in plain text
- Millions of utility customers’ passwords stored in plain text
참고로, 데이터베이스에는 다음과 같은 리스크가 존재할 수 있어요.
- 누군가 데이터베이스에 접근해 정보를 빼내려 하는 행위
- 쉽게 추측이 가능한 취약한 비밀번호를 가진 데이터베이스
- 백업 보안. (30일 주기로 백업 후 S3에 저장한다면, S3에 대한 보안을 고려하지 않고 지나칠 수 있어요.)
- SQL Injection
- 개발자가 로그를 실수로 남겨 두어 악용될 가능성도 있어요.
- ORM 또는 serializer를 잘 못 사용해 유저 정보가 노출될 수 있음.
일반 텍스트로 된 비밀번호는 공용 와이파이를 이용해 전송하고, 이 와이파이가 암호화 되지 않은 경우에도 노출 가능성이 있습니다.
SQL Injection에 대해서도 언급을 했는데, 이것에 대한 원인은 unsanitized 상태인 악의적인 HTML Input SQL 명령어가 API server를 거쳐 직접 데이터베이스로부터 정보를 취하도록 하기 때문입니다.

SQL Injection에 대한 리스크를 줄일수 있는 방법 몇 가지는 아래와 같아요.
- Validate Inputs
- Sanitize Inputs
- ORM 사용 등
- Prepared SQL statement 사용
Brute Force Attack
로그인 시 유저가 잘못된 정보를 입력하면 unauthorized reponse를 보내고, 이 경우 유저는 다시 로그인을 시도할 거에요. 이를 악용해 아래와 같이 간단한 코드로 비밀번호를 변경해 가며 로그인을 계속 시도해 볼 수 있는데, 이를 Brute Force Attack이라 해요.
def try_password(password):
user = {"username": "target", "password": attempt)
r = requests.post(`{{host}}/login`, data = user)
with open("nist_10000.txt", newline="") as bad_passwords:
nist_bad = bad_passwords.read().split("\n")
for attempt in nist_bad:
try_password(attempt);
봇을 이용해 짧은 시간에 매우 많은 요청을 보내게 되고, 운이 좋으면 일치하는 비밀번호를 찾을 수 있을거에요. 하지만, 아래와 같이 간단한 방법으로 이 위험을 크게 감소시킬 수 있어요.
- 로그인 시도 횟수를 제한하기
- 예상하기 쉬운 비밀번호 사용 거부하기
- 비밀번호가 적당히 복잡해 질 수 있는 정책 사용하기
- 공격에 대한 모니터링. 급작스러운 트래픽 변화가 감지되면 어떠한 조치 취하기
로그인 회수 제안을 하는 경우, 나쁜 봇으로 인해 특정 유저의 계정이 잠기계 되면 실제 유저가 불편을 겪을 수 있어요. 이에 대한 대안책으로 CAPTCHA(Completely Automated Public Turing test to tell Computers and Humans Apart )를 많이 이용하게 되었어요. 사람이 인지하기 쉽고 봇은 파악하기 어려운 텍스트를 입력하게 하는 벙식이에요. 아마도 웹사이트를 이용하며 여러번 마주쳤을 거에요. 하지만, 최근 기술의 발달로 봇도 이를 해결할 수 있다고 합니다. 참고로, 대안책으로 구글의 reCAPTCHA가 있는데 방문객과 사이트의 상호작용을 점수로 환산해 사람과 봇을 구별한다고 합니다.
Data Handling and Logging
개발을 하며 Data Handling 및 Logging 작업에서도 실수를 하기 쉬운데, 동시에 쉽게 간과할 수 있는 부분이에요.
데이터베이스에서 가져오는 데이터 중 전화번호 등과 같은 유저의 민감한 정보를 포함하는 경우가 있습니다. 이러한 경우 서버에서 현재 작업에 꼭 필요한 정보다 serialize 하도록 주의해야 합니다.
애플리케이션 개발을 하며 디버깅을 위해 또는 현제 시스템의 상태 파악을 위해 로그를 사용하게되요. 로그인 시도나 이와 관련된 ID, IP 주소와 같은 로그인 시도를 한 source 에 대한 정보, 요청 자원에 대한 로그를 남길 수 있어요. 하지만, 유저와 관련된 민감한 정보를 로그로 남기는 것은 악용될 수 있기 때문에 피애햐 합니다.
이와 같은 개발자들의 사소한 실수가 의외로 빈번하다고 하니, 작업시 유의하면 좋겠어요. 위에서 공유했던 링크에서 보듯이 Facebook에서도 일반 텍스트로 저장한 비밀번호를 로그로 남겼던 사례가 있으니 조심해야 겠어요.
Encryption
비밀번호를 일반 텍스트로 저장하면 안되기 때문에, 다른 방법이 필요합니다. 그래서 암호화된 비밀번호를 사용하는데, 기본적으로 텍스트를 섞는 방식이 사용되고, 암호화된 텍스트는 본래의 값으로 다시 되돌릴 수 있습니다. 가장 기초적인 암호화 방식으로 Simple Substitution이란 방식이 있어요.

알파벳을 나열 후 키워드 단어를 맨 앞으로 옮기고, 뒤의 나머지 알파벳도 차례로 순서를 옮기는 방식이에요. 이 방식은 해독하기가 쉬워요. 다음 단계로 Polyalphabetic Cypher란 방식이 있어요. 단순히 Simple Substitution 방식을 n
만큼 곱해 조금 더 복잡하게 만든 방식이에요. 하지만, 이 방식도 여전히 해독이 쉽습니다. 이 방식은 2차 대전 당시 독일군에서 사용되었는데, Alan Turing은 당시 독일군에서 사용한 Enigma Machine
을 해독하는 알고리즘을 만들어 연합군 승리에 기여했다고 해요.

우리는 애플리케이션에서 사용할 암호화 방식에 대해 알아봐야 해요. 실제 서비스에서 사용하는 방식은 크게 네 부분으로 나누어 볼 수 있습니다. 일반 텍스트로 된 비밀번호 입력 값과, 이를 암호화 한 텍스트, 그리고 암호화 하는데 사용되는 알고리즘 방식과 암호화 키가 있습니다. 이 키는 보통 아무나 정보에 접근하지 못 하도록 사용됩니다. 암호화 시 사용되는 일반적인 3가지 알고리즘 방식은 아래와 같이 3DES, Blowfish, AES가 있어요. 3DES는 70년대부터 사용되었으며, 미국 정부에서 정보를 암호화 하기 위해 사용된 방식이라고 해요.

이 방식도 기본적으로 Simple Substitution과 같은 방식이고, 컴퓨터나 사람이 해독이 어렵도록 복잡성을 추가한 것이에요. 사용되는 알고리즘은 Feistel Block Cipher와 같은 블록 암호를 기본으로 합니다.

기본적인 작동 방식으로 우선 일반 텍스트로 된 비밀번호를 인풋으로 받으면, A, B 두 파트로 나눕니다. A는 암호화 해주는 함수에 암호화 키와 함께 인풋으로 주어지고 암호화된 텍스트로 변환됩니다. 그리고 B 와 함쳐지고, 이 함쳐진 값이 다시 다음 단계에서 암호화 함수의 인풋으로 주어집니다. 이러한 과정은 글보다 위의 그림을 보면 좀 더 쉽게 이해할 수 있을거에요.
암호화 과정에 사용되는 키는 안전하게 보관되어야 합니다. 또한 잃어버리게 되면 암호화된 텍스트를 해독할 수 없기 때문에 주의해야 해요.
Using Encryption
유저 가입 시 비밀번호를 저장할 때 암호화 해서 앞서 언급했던 리스크를 최소화 해야 합니다. 이런 과정을 통해 누군가 데이터베이스에서 암호화된 비밀번호를 추출해 로그인 시도를 해도 성공할 수 없게 됩니다.

그럼에도 리스크가 온전히 사라진 것은 아니에요. SQL Injection이나 백업 시 보안 문제 등의 위험을 감소 시킬 수 있지만, 암호화 키와 데이터베이스에 접근 가능한 엔지니어가 나쁜 의도를 가졌다면 유저 정보를 가져와 복호화 할 수 있을거에요. 또한, 서버 자체에서도 리스크가 없지는 않습니다. 암호화 키나 비밀번호가 로그로 남거나 serialize 된 상태로 클라이언트에 응답으로 보내질 수 있어요.
카드 번호나 주민 번호 등의 데이터가 전송 중에도 리스크는 존재합니다. 전송 중 데이터도 암호화 과정을 거치는데, 이때 사용하는 방식을 Asymmetric Encryption이라고 해요.
Asymmetric Encryption
서비스 간 오고가는 데이터 또한 위험에 노출될 가능성이 있어요. 일반적으로 네트워크 상 오고가는 데이터는 일반 텍스트 패킷이고, 이 패킷은 이동 중 노출될 우려가 있어요. 위에서 알아본 암호화 과정에서 암호화와 복호화 시 같은 키를 사용했어요. 이보다 좀 더 복잡성을 띄는 방식이 공개 키 암호 방식(비댕칭 암호 방식)이에요. 공개 키 암호 방식에서는 공개 키와 비밀 키가 존재합니다. 비밀 키는 데이터를 암호화 하는데 사용되고, 공개 키는 다른 서비스에 전달해 암호화된 데이터를 복호화 할 수 있도록 합니다. HTTPS, TSL/SSL과 같은 네트워크 프로토콜에서 이러한 방식이 사용되고 있어요.

Hashing
해싱은 Encryption과 비슷하지만, 단방향으로 데이터를 암호화 하는 함수라는 점에서 다릅니다. Encryption에서 암호화 키를 이용해 암호화된 텍스트를 다시 복호화 할 수 있었어요. Hashing 에서는 암호화 키가 없어 원본 텍스트로 복호화 할 수도 없어요. 일반적인 Hashing 함수로는 bcrypt, scrypt, SHA-1, MD5가 있습니다.

Hashing 이용 시 데이터베이스에는 비밀번호 Hashing 후의 값을 저장합니다. 유저가 로그인 시 입력한 비밀번호를 Hash Function을 거쳐 변환합니다. 이 값을 Message Digest 라고도 하는데, 이 변환값을 데이터베이스의 저장값과 비교해 비밀번호의 유효함을 판단합니다.
Hash를 사용하면 유저 정보 노출의 우려가 없어진 것 같이 보일 수 있지만, 이 때에도 리스크가 존재해요. 겉으로 보기에 비밀번호가 Hashing Function을 거치면 다시 원래 값으로 돌릴 수 없지만, hashing function이 좋지 못 하면 rainbow table이라 불리는 방법을 이용해 비밀번호를 알아낼 수 있기도 해요.
일반적으로 많이 사용하는 단어들 리스트를 준비하고, 이 리스트를 loop을 돌며 Hashing Function을 이용해 변환 후, hash는 key로 hash 전 단어는 value로 dictionary object 에 저장을 해요. 만약 많은 수의 단어를 반복문을 이용해 hashing이 가능할 정도로 hashing function의 연산이 비싸지 않다면, 여기서 취약점이 생길 수 있습니다.

모든 hash가 같은 방식으로 만들어 진것이 아니라고 합니다. 위와 같은 위험을 줄이기 위해 실제 제품에서는 bcrypt와 script 또는 이보다 높은 단계의 hashing function을 이용해야 해요.
Hashing with Salts
Hashing Function을 이용해 비밀번호를 저장해도, Hashing Function은 같은 인풋이 들어오면 같은 아웃풋을 반환하기 때문에 Rainbow Table Attack에 대한 리스크가 있다는 것을 알았어요.
여기서 인풋값을 변경함으로써 같은 hash가 존재하지 않도록 해 위 위험을 경감시킬 수 있습니다. salt라고 불리는 랜덤 string을 인풋값에 추가해 이를 구현할 수 있어요. salt를 추가해서 인증 로직에 변경 사항은 없고, 데이터베이스에 추가로 salt 까지 저장을 해 줍니다.

salt 사용시 string의 길이가 충분히 길어야 하며, 새로운 비밀번호 입력 시 salt도 초기화 되어야 합니다. 그리고, salt 자체는 임의의 값이어야 해요. 임의의 salt 생성을 위해 Salt Round라는 프로세스에 대해 알아야 해요.
Salt Round에서 각 Round는 이전의 결과인 hash를 인풋으로 연삽합니다. Salt Round는 cost factor로 이에 따라 hash 생성을 위해 얼마나 오랜 시간이 걸리는지 결정이 돼요. Cost factor가 증가하면 연산이 더 늘어나 시간이 더 소요됩니다. 로그인과 같은 일회성에서는 큰 차이를 못 느끼겠지만, Brute force나 Rainbow Table과 같은 시도에는 그 차이가 매우 커집니다.
추가로, Secret을 이용해 Hash 알고리즘을 내부적으로만 아는 방법으로 변경해, Hash 알고리즘에 한 층 더 복잡성을 추가할 수 있어요.
비밀번호 방식에서 오는 문제점에 대해 어느 정도 살펴보았고, 또한 현실적으로 이 방식을 사용은 해야 하기 때문에 리스크를 감소시키는 방식에 대해서도 알아보았어요. 일반 텍스트로 비밀번호 저장 시 문제점, 이에 대한 대안책으로 Encryption, Hashing, Hashing with Salt에 대해 간략히 살펴보았어요.
API 서버에서 발생할 수 있는 logging, serlization 관련 문제 및 서비스 간 데이터 전송 중 발생할 수 있는 문제에 대해서도 알아보았어요. 보통 인증 및 비밀번호 관련 전문 팀이 구성되지 않은 이상, 인증 기능을 직접 구현하는 것은 많은 위험에 노출될 수 있기 때문에, 잘 구현된 서비스를 이용하는 방법도 있습니다.
Access and Authorization
지금까지의 글에서 "누가 요청을 보냈는가"에 대해 알아 보았어요. 애플리케이션 개발 시 일부 데이터는 다른 데이터보다 더 민감한 정보를 포함할 수 있고, 또는 일부 유저만 접근 권한이 있을 수 있어요. 그래서, 여기서는 "요청을 보낸 사람이 무엇을 할 수 있는가"에 대해 알아보도록 할 거에요. 실제 세계에서 비교를 해 보면 운전자가 운전하는 차량에 적합한 면허를 소지하고 있는지, 또는 술집에서 주류 주문 시 나이를 확인하는 절차와 같다고 생각할 수 있습니다.
특정 유저에게 특정 행동에 대한 권한만을 주어 이를 구현할 수 있어요. 일부 유저가 허용된 action만 취할 수 있도록 특정 Permission을 부여하는 거에요. 이 때, Permission 은 제한되고 타이트하게 관히라는 것이 시스템 운영상, 또 여러 목적에 맞게 사용하기 좋다고 해요.

시스템이 커지게 되면 각 유저마다 특정 Role을 부여 받는 경우가 일반적이에요. 우리는 각 Role 마다 허용된 권한을 부여해 특정 Role에 특정 권한을 제한할 수 있어요. 이에 따라 데이터베이스를 생성한다면, 아래와 같이 Role 별로 Permission을 부과해 볼 수 있어요.

User Table에 Foreign Key를 이용해 Role Column을 추가했고, 특정 유저에게만 별도의 Permission을 추가할 수도 있도록 Permission Column도 추가했어요.
Decoding JWT using Javascript
프론트엔드에서 전달한 JWT를 API 서버에서 validate 하는 방식에 대해 알아보았지만, JWT는 base64로 인코딩 되었기 때문에 클라이언트에서도 이를 확인할 수 있습니다. 토큰을 클라이언트에서 decoding 후 payoload의 permission 정보에 따라 UI를 다르게 보여줄 수도 있을거에요.
function parseJwt(token) {
const base64Url = token.split('.')[1];
const base64 = base64Url.replace(/-/g, '+').replace(/_/g, '/');
const jsonPayload = decodeURIComponent(
atob(base64)
.split('')
.map(function(c) {
return '%' + ('00' + c.charCodeAt(0).toString(16)).slice(-2);
})
.join('')
);
return JSON.parse(jsonPayload);
}
Alternate Atrack Vectors
앱과 시스템이 발전함에따라 보안에 대한 사항도 계속 변화해야 합니다. 마지막으로 보안 이슈 관련해 가능한 사전에 방지할 수 있는 방법에 대해 알아보도록 할게요.
Resource
- Web Authentication API
- Auth0 Identity Providers
- iOS Biometrics
- Oath2
- Google Authenticator
- Malware Google Permissions
- Dance Dance Authentication
- Base64 Encoding
- Google Identity Platform
- jwt.io
# Security Considerations
- Why Cookies Aren't Necessarily Safer
- OWASP XSS Cheat Sheet
- Http Only Cookie
- Input Sanitation
- React + Redux + JWT Tutorial
# Passwords
- List of The Most Common Passwords
- Top 10 Password Policies and Best Practices for System Administrators
- Bandit CLI Wargame
- Making a Faster Cryptanalytic Time-Memory Trade-Of
- RBAC vs PBAC
- Code Review Best Practices
- AWS IAM Best Practices
- Command line integration with Newman
- I'll Let Myself In: Tactics of Physical Pen Testers - WildWest Hackin' Fest
- Kitboga: A YouTuber who engages with social attacks